Elarva Featured on InfoQ
Video introducing Elarva concepts
Christian Columbo - Erlang - a monitoring-oriented programming language from Erlang Solutions on Vimeo.
Runtime Verification
Robustness and reliability are key factors in the success of the deployment of
security-critical systems. Testing, fails to address these concerns adequately
since not all possible execution paths are covered. On the other hand, verification
- the analysis of all execution paths - is usually unfeasible due to the large
state space of such systems. Runtime-verification addresses the issue by enabling
formal verification of the system during its execution. An adequate logic and
language to express typical security properties is a prerequisite to enable runtime
verification.
ELARVA
The Larva monitoring tool has been successfully applied to a number of industrial Java systems, providing extra assurance of behaviour correctness.
Given the increased interest in concurrent programming, we propose Elarva, an adaptation of Larva for monitoring programs written in Erlang, an
established industry-strength concurrent language. Object-oriented Larva constructs have been translated to process-oriented setting, and the
synchronous Larva monitoring semantics was altered to an asynchronous interpretation.
Overview
- Specification - As in Larva, the chosen specification is DATEs, a logic based on
symbolic automata which offers a high degree of expressivity. Being designed for runtime verification it requires much less computational resources
than having a logic to be decidable over all execution paths.
- Instrumentation - In Larva, the instrumentation is tackled via aspect-oriented programming which
uses joinpoints (i.e. identifiable points in the code) defined by a pointcut (i.e. rule
to which a number of joinpoints should match) to capture events. This is achieved
because Java, the implementation language used in Larva, supports aspect-oriented
programming through AspectJ. Message passing concurrency languages do not
support aspect-oriented programming therefore we had to use another approach.
We had two options, either use hand instrumentation i.e. inserting specific code in
the target system for each occurrence of a particular event, or using the tracing
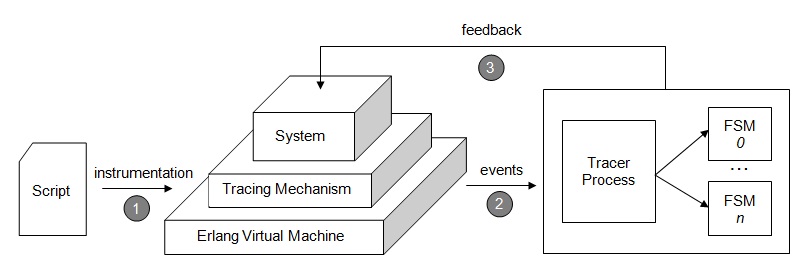
mechanism of Erlang. We opted for the Erlang tracing mechanism because it
gives us an elegant way how to capture events without modfying the target system
while hand instrumentation would result in the cluttering of the target system.
- Monitoring - The Erlang tracing mechanism does not suspend the system while a trace event is
triggered therefore the target system will continue its execution while the Erlang
tracing mechanism generates trace events and sends them to the tracer process.
This requires us to adopt an asynchronous monitoring mode where the target
system and the monitoring code are both running in parallel but there exists a
delay between the occurence of events and the delivery of trace messages.
When the Erlang tracing mechanism is activated the Erlang virtual machine sends trace messages to a tracer process. This tracer
process is the central and most important part of our monitoring code. The Erlang
virtual machine can only send trace messages to a single process thus at any one
time there is only one tracer process. As a consequenece, the tracer process is
responsbile for receiving trace messages and generating meaningful events which
are forwarded to the appropiate FSMs. If the erlang virtual machine could send
trace messages to more than one process we could eliminate the tracer process
and let each FSM receive its pertaining events.
- Handling Violations - Since we adopted an asynchronous monitoring mode, we are restricted with
respect to the actions that can be taken upon a violation detection because upon
a violation detection the target system will continue execution with the possibility
of doing more damage (for example exposing sensitive data etc.). Even though
we cannot take an immediate action upon a violation detection we can take action via the Supervisor behaviour which can restart the
target system to limit the damage. If the target system is designed with built-in
recovery strategies (i.e. routines that can rearrange the system’s state), we can
trigger these routines (for example by a function call or by a message) as an
action upon violation detection.
- Mitigating the impact of verification - The monitoring code induces an amount of overhead on the target system.
We have to minimise this overhead as much as possible. One way to minimise the
induced overhead is to adopt a distributed monitoring approach where the target
system runs on Erlang node while the monitoring code resides on a different
Erlang node and on a separate machine with dedicated hardware.
Future Directions
- Extension to ELarva Specification - We can improve the expressivity of ELarva specification by handling real-time
properties i.e. the ability of measuring the real-time between system events. Realtime
properties can be implemented by timers which can trigger events. However extending ELarva to handle real-time properties is not so straight forward because
real-time properties are very sensitive to overheads and more error-prone
due to their strict timings.
- Reducing Further the Overhead - In the performance benchmark we obtained knowledge of the degree of induced
overhead by ELarva. We proved that for considerably large properties this
overhead can be reduced via a distributed monitoring approach where the target
system and the monitoring code run on seperate Erlang nodes and on seperate
machines. We have also identified that this overhead can be further reduced by
using more light weight FSMs than the gen fsm behaviour which despite being
part of the OTP framework, thus giving us advantages like well-tested, it can be
some what heavy on the target system.
- More User-Friendly Presentation of Monitoring Results - Currently the output of the monitoring code is being outputted to the Erlang
shell. It would be ideal to save the output in a file and have some functions that
parse the output file to give a brief summary of where most of the problems would
lie. If this brief summary is not sufficient for the user he can still view the whole
output of the monitoring code to have a better insight of what might have gone
wrong.
|