Transforming Regular Grammars to Equivalent
Finite State Automata
Algorithm
The algorithm now follows:
- construct an
 -free regular grammar G' from G
(see relevant section);
-free regular grammar G' from G
(see relevant section);
- create a FSA M, with a state for every non-terminal in
G'. Set the state representing the start symbol to
be the start state;
- add another state D, which is terminal;
- if the production S
 is in G' (where S is
the start symbol of G', set the state representing
S to be final;
is in G' (where S is
the start symbol of G', set the state representing
S to be final;
- for every production AaB in G, add
a transition from state A to state B labelled
with terminal a;
- for every production Aa in G, add a
transition from A to the terminal state D
Example
Construct a FSA M that recognises the language generated by
the following regular grammar G:
| S | | a | aA | bB | |
| A | | aA | aS |
| B | | cS | |
where S is the start symbol.
- Construct an equivalent -free grammar:
| S1 | | a | b | aA | bB | |
| S | | a | b | aA | bB |
| A | | a | aA | aS |
| B | | c | cS |
where S1 is the start symbol.
- create a FSA M, with a state for every non-terminal in
G' - {S1, S, A, B}. S1,
being the start symbol is set to be the start state:

- add another terminsl state D0:

- since S1 was in the grammar, state S1 is also set to
be final:

- for every rule of the form AaB, we add a transition
from state A to state B labelled a:
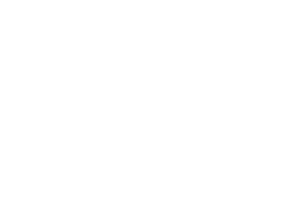
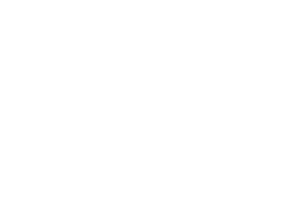
- for every rule of the form Aa, we add a transition
from state A to state D0 labelled a:
Exercises
Construct finite state automata equivalent to the following
regular grammars:
-
| G = < | { a, b, c }, |
| | { S, A, B, C }, |
| |
| { |
S |
|
aA | bC, |
| |
A |
|
aA | bB |
, |
| |
B |
|
bB | b |
, |
| |
C |
|
cB | cC |
}, |
|
| | S > |
-
| G = < | { a, b, c }, |
| | { S, A, B, C }, |
| |
| { |
S |
|
aA | bC |
, |
| |
A |
|
aA | aS, |
| |
B |
|
b, |
| |
C |
|
cB | cS }, |
|
| | S > |
-
| G = < | { a, b, c }, |
| | { S, A, B, C }, |
| |
| { |
S |
|
aA | bC |
, |
| |
A |
|
aA | aS, |
| |
B |
|
b, |
| |
C |
|
cB | cS }, |
|
| | S > |
-
| G = < | { a, b }, |
| | { S, A }, |
| | |
| | S > |
-
| G = < | { a }, |
| | { S }, |
| | { S},
|
| | S > |